
主要内容
1.理解总体分布的非参数估计
2.实现KNN算法(K-Nearest Neighbour Algorithm)


3.讨论Density Estimation based on Parzen Window含义和过程
密度估计:给定n个数据样本x1,x2,....,xn,我们可以估计概率密度函数p(x),对于新的样本x就可以计算出相应的p(x),这个过程就是密度估计。
密度估计的基础是:一个向量x落入到区域R的概率为
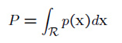
假设R非常小,所以p(x)的变化也很小,上面的公式就改写为:
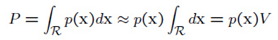
其中V是R的“体积”。 另一方面,假设x1,...,xn是根据密度函数p(x)独立取的n个样本点,其中有k个样本点落入到区域R中,关于R的概率就为:
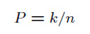
这样就可以得到一个p(x)的估计函数:
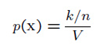
Parzen window密度估计
假设R是以x为中心的超立方体,h为这个超立方体的边长,在2D的方形中有V=h*h,3D的立方体中有V=h^3。
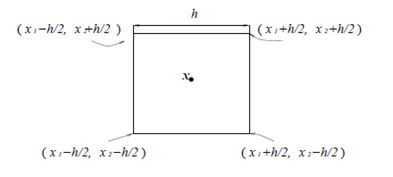
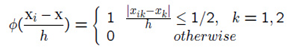
给定上面的公式,表示的是xi是否落在方形中。
Parzen概率密度估计公式的表示如下:
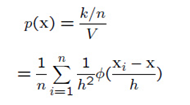
其中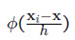 被称作窗口函数(window function)。
被称作窗口函数(window function)。
同时可以对窗口函数做一定的泛化,就有其他的Parzen window密度估计方法。
例如在1D的情况下使用Gaussian函数:
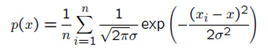
这种方法就相当于将n个点为中心的高斯函数计算平均。其中标准差σ需要预先设定。
例子:
给定五个点:x1=2, x2=2.5, x3=3, x4=1, x5=6, 计算x=3位置的Parzen概率密度函数,采用σ=1的高斯函数作为window function。
计算过程如下:
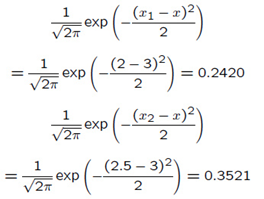
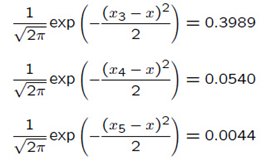
采用图形的方式进行显示,并假设上面的5个点对整个密度函数做出相等的贡献:
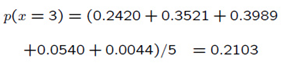
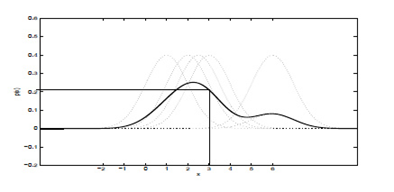
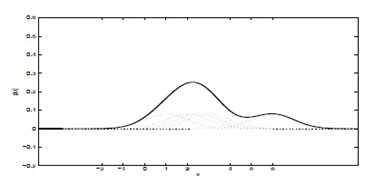
采用Parzen Window对这个五个点估计得到的概率密度函数为:
-----------------------------------------------------------------------------------------------
中文PPT
英文PPT

