算法原理
冒泡排序算法的运作如下:
1、比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2、对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3、针对所有的元素重复以上的步骤,除了最后一个。
4、持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
白话经典算法系列之冒泡排序的三种实现
冒泡排序是非常容易理解和实现,,以从小到大排序举例:
设数组长度为N。
1.比较相邻的前后二个数据,如果前面数据大于后面的数据,就将二个数据交换。
2.这样对数组的第0个数据到N-1个数据进行一次遍历后,最大的一个数据就“沉”到数组第N-1个位置。
3.N=N-1,如果N不为0就重复前面二步,否则排序完成。
按照定义很容易写出代码:

下面对其进行优化,设置一个标志,如果这一趟发生了交换,则为true,否则为false。明显如果有一趟没有发生交换,说明排序已经完成。
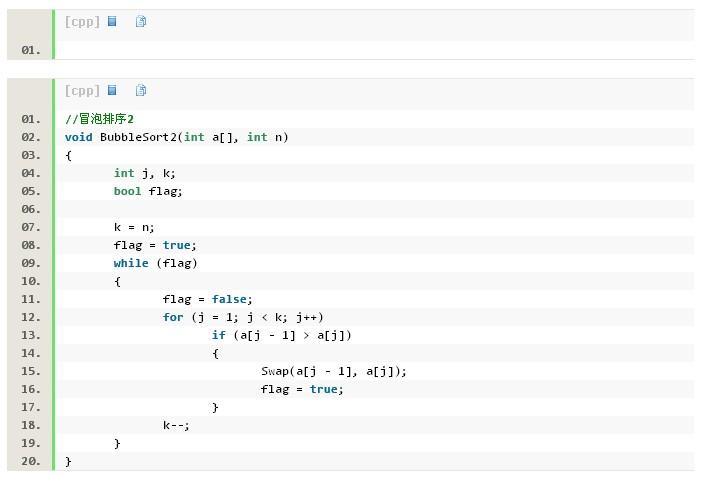
再做进一步的优化。如果有100个数的数组,仅前面10个无序,后面90个都已排好序且都大于前面10个数字,那么在第一趟遍历后,最后发生交换的位置必定小于10,且这个位置之后的数据必定已经有序了,记录下这位置,第二次只要从数组头部遍历到这个位置就可以了。

冒泡排序毕竟是一种效率低下的排序方法,在数据规模很小时,可以采用。数据规模比较大时,最好用其它排序方法。



